



Hey everyone, this will be the second part of my bash series. In this blog post, we'll discover anything that we can do with Bash. Let's get started
Linux directories
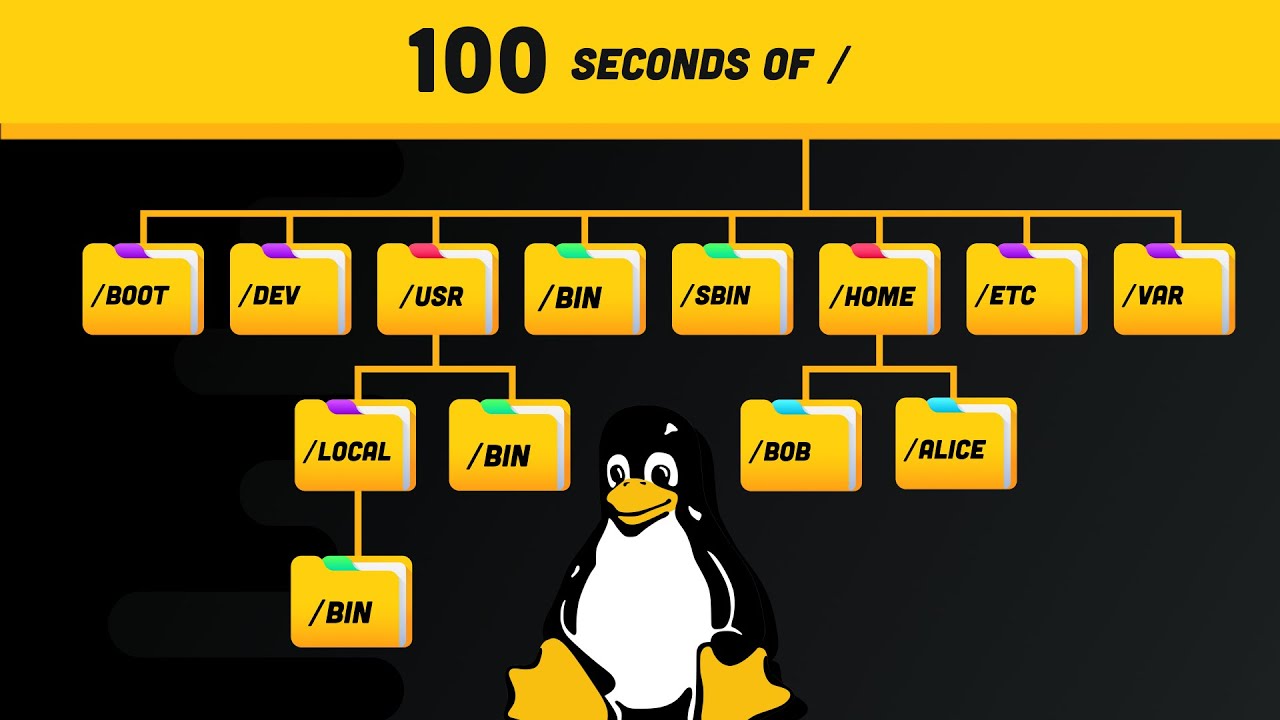
Based on this, I'll give you a brief summary
- /bin contains essential executables that are essential for the entire system

- /sbin also contains executable binary that should only executed by root user

- cd ~ also has binary executable files and intended for local users

If you want to know where the binary is, you can run this command
which node;
/Users/vincenguyen/.nvm/versions/node/v16.19.0/bin/node
which npm;
/Users/vincenguyen/.nvm/versions/node/v16.19.0/bin/npm
etc (editable text configuration)

Command Subsitution
Command substitution allows us to use the output of a command as an expansion
echo $(ls);
file $(ls /usr/bin | grep zip)
cd $(ls | grep "antd")
Find files with simple search
ls -l | grep "filename"
Advantages
Simple and straightforward for basic file listing tasks.
Faster than
findfor listing files in a single directory.
Disadvantages
Limited to the current directory (unless used with
ls -Rfor recursive listing).Less flexible compared to
findwhen it comes to specifying search conditions.

Find files in terminal with bash
Extremely useful when searching for file in node_modules

The find command has to be in the following order:

The Find command returns all of the files, folders, or directories from the search result within a particular hierarchy.
find . -name "*.md" (. means current working directory)
find /home -iname "file.txt"
We can also have a combination of different types
find . -type f -name "*.JPEG" | wc -l
How many files that has JPEG extension ?
find . -type d | wc -l
How many folder in your current working directory?
Real example
find . name license.csv | xargs cat | sort | uniq > lisense-all.csv
There're so many cases that we can tell bash to lookup files for us
Give me a match files that content or attribute has been modified
x minutes ago?
Give me a match files that belongs to x Group ?
Give me a match files that match a specified wildcard pattern ?
Give me a match files that have permissions set to specified mode ?
Give me a match files that match a type ?
Networking and the internet
SSH is another protocol that allows us to communicate between different computer (share files , modify remote computers) over the internet



curl (Client URL Request Library)
curl is a command-line tool used for transferring data to or from a server. It supports various protocols, including HTTP, HTTPS, FTP, and others. The tool allows you to send HTTP requests, download files, and interact with APIs or web services directly from your terminal or command line.

In this section, I'll walk you through how to interact with HTTP and HTTPS protocols. of course, there are many other protocol likes FTP,FPS, etc that I will not cover
Download the content of a specified URL
curl domain-name

Download the HTML
curl -o domain-name

Inspect HTTP response from web-server( -i means inspect)
This will send a HEAD request instead of a GET request. Head requests just get the endpoint metadata and don't actually do a full request. This is a quick way to see if a server is ready to respond to a given request

Inspect TLS handshake

The best thing is we can use curl without using POSTMAN to test our API
curl -H "Authorization: Bearer your_token_here" http://example.com/api/resource
Edge/Chrome/Firefox curls
One very cool feature of modern browsers is the ability to copy requests out of your network panel in your dev tools as curl requests and then be able to replay them from the command line. I do this all the time to properly formulate requests and get all the auth headers right.

wget
Frequently, you will want to send requests to the Internet and/or network. The two most common tools to do that are wget and curl. Both of these are common to find in use, so I'll take the time to show you both, but they do relatively the same thing. In general, I'd suggest you stick to using curl; it's a more powerful tool that can do almost everything.
Package manager for MAC OS(CLI tool)q
The Missing Package Manager for macOS (or Linux). Think of it as npm for MAC-OS
Simplicity and Convenience
One Command Installations: Installing software with
brewis as simple as typingbrew install <package_name>. You don’t need to manually download, extract, compile, or configure software.Easy Uninstallations: Uninstalling a package is just as simple with
brew uninstall <package_name>, avoiding leftover files or dependencies.
Dependency Management
Automatic Handling of Dependencies: When you install a package, Homebrew automatically downloads and installs any required dependencies, ensuring the software works properly.
Safe Updates:
brewhandles dependencies carefully during updates, so you don’t end up with broken software because of missing or incompatible libraries.
Search for all packages in brew

Formula
Formula often deals with CLI software.

Casks
Is an extension of homebrew that allows us to install macOS native application (google chrome or things like that)

Info about the packages that brew has already installed

Info about the packages that we're going to install

Homebrew handles dependencies automatically, ensuring that required libraries or tools are installed along with the requested package.
Uninstall the package
brew unistall tree
Override OS system
We have the grep commandline from the OS and grep from brew packages

Updating the packages installed by brew


Compressing Files
In the history of computing, there has been a struggle to get the most data into the smallest available space, whether the space be memory, storage devices, or network bandwidth
Data compression is the process of removing redundancy from data. Let’s consider an imaginary example. Say we had an entirely black picture file with the dimensions of 100 pixels by 100 pixels. In terms of data storage (assuming 24 bits, or 3 bytes per pixel), the image will occupy 30,000 bytes of storage: 100 × 100 × 3 = 30,000.
An image that is all one color contains entirely redundant data. If we were clever, we could encode the data in such a way as to simply describe the fact that we have a block of 10,000 black pixels. So, instead of storing a block of data containing 30,000 zeros (black is usually represented in image files as zero), we could compress the data into the number 30,000, followed by a zero to represent our data. Such a data compression scheme, called run-length encoding, is one of the most rudimentary compression techniques. Today’s techniques are much more advanced and complex, but the basic goal remains the same: get rid of redundant data.
Compression algorithms (the mathematical techniques used to carry out the compression) fall into two general categories: lossless and lossy. Lossless compression preserves all the data contained in the original. This means that when a file is restored from a compressed version, the restored file is exactly the same as the original, uncompressed version. Lossy compression, on the other hand, removes data as the compression is performed to allow more compression to be applied. When a lossy file is restored, it does not match the original version; rather, it is a close approximation. Examples of lossy compression are JPEG (for images) and MP3 (for music). In our discussion, we will look exclusively at lossless compression, since most data on computers cannot tolerate any data loss.
gzip compresses or Expands files

Uncompress the files

View the compressed files
Because it's a compressed file, we can not see it in a normal format

Compress it back to index.txt and output it as less. gunzip command will assume that the file ends with .gz we don't need to explicitly tell the computers to do that for us

-c means write standard output and keep original files

Archiving Files
Archiving files involves gathering multiple files into a single file for easier storage and transfer. This can help keep related files together and make them easier to manage. Archiving does not necessarily reduce the size of the files, but it can make them more convenient to work with as a group.
Compressed files must be decompressed before they can be used, while archived files can often be used directly without extraction. In summary, archiving is primarily for organizing and grouping files, while compressing is for reducing file size to save space and speed up transfers.
mkdir -p playground/dir-{00{1..9},0{10..99},100}
touch playground/dir-{00{1..9},0{10..99},100}/file-{A..Z}


tar -cf playground.tar playground
c means create an archive from a list of files/ directories
f means to you want to provide the file name


View the tar file

We can use -tvf (verbose mode) to see more information.
Extract the tar file

Compressed archieve files

-z means to compress to gzip, so now we will have the tarball
